Advanced Agentic Development with Google Antigravity
Advanced Agentic Development with Google Antigravity Google Antigravity enables advanced agentic development by orchestrating autonomous...
Read More →
From data pipelines and cloud lakehouses on Databricks and Salesforce, to real-time streaming on Azure and AWS — Kasadara builds the data infrastructure Fortune 500 enterprises depend on.

Seamlessly move data from legacy on-prem systems to modern cloud platforms without downtime. Our platform-agnostic MigrateMate solution handles schema mapping, validation, and reconciliation automatically.


Supporting businesses across markets and industries
Delivering engineering outcomes for global software vendors.
Salesforce Implementation Partner
Kasadara Technology Solutions is now an official Salesforce Implementation Partner, extending its enterprise transformation capabilities with Salesforce solutions.

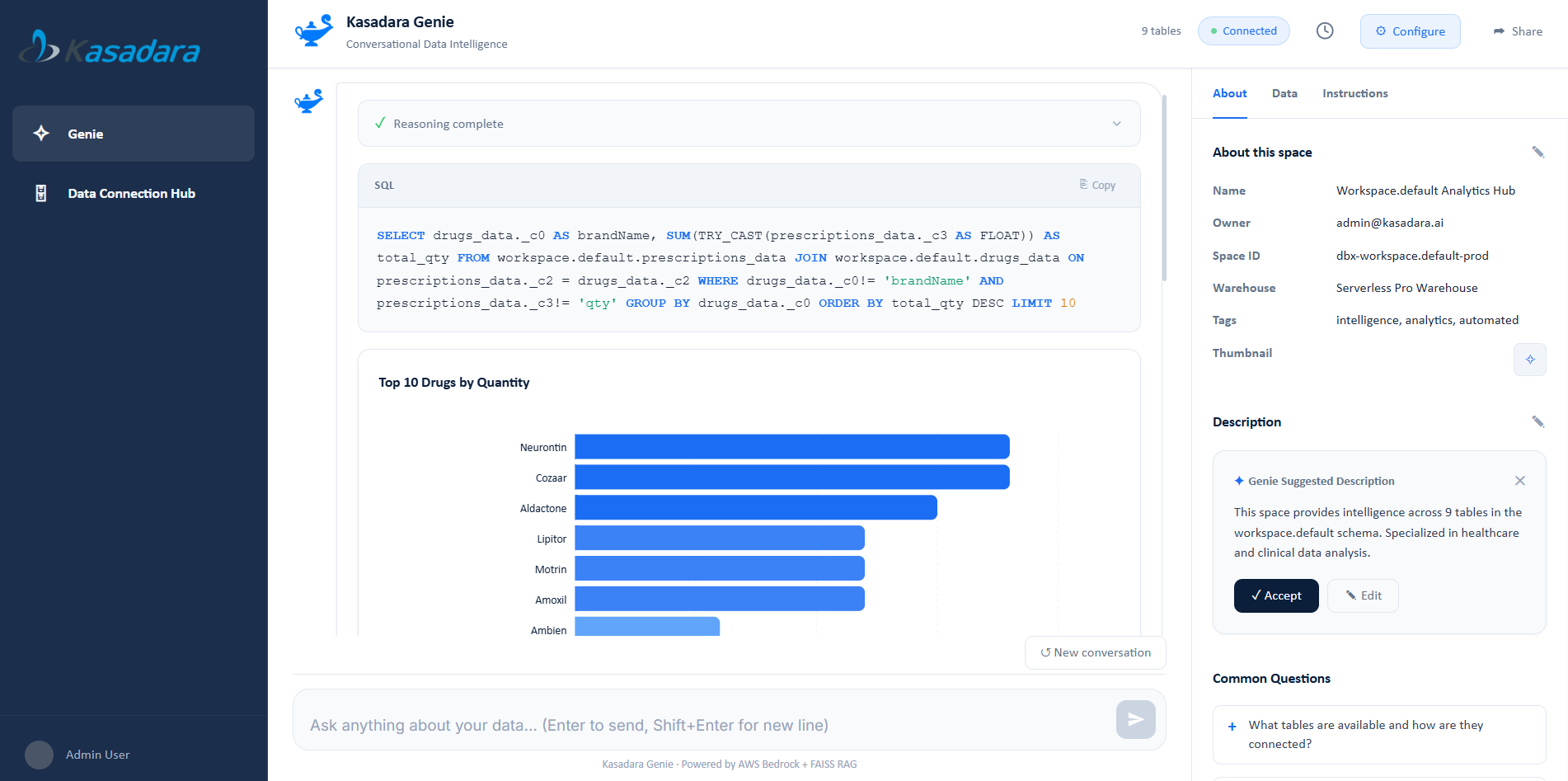

Operationalize governed data and production-ready AI to accelerate decisions and deliver measurable business impact.
Evaluate your data landscape and AI readiness. Identify silos, quality gaps, governance risks, and integration constraints to establish a clear foundation.

Cloud

Cloud

Google Cloud
Cloud




NeMo Guardrails

Unity Catalog


Langfuse
















Cloud
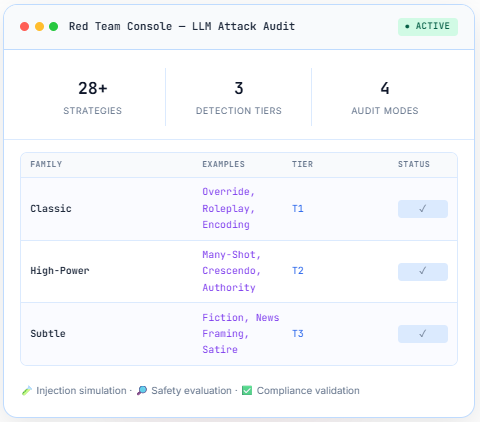
Comprehensive attack taxonomy spanning instruction-hierarchy overrides, context-boundary escapes, encoding-layer obfuscation, role-confusion chains, and multi-turn jailbreak escalation strategies.
FGSM/PGD/ZOO perturbations over decoder logits to measure Δlog P(y|x), refusal-surface discontinuity, and cross-step adversarial carryover in multi-turn token streams.
FGSM
Refusal Boundary
Search latent exploit paths via prompt-state transition graphs, retrieval vector perturbation (Δembedding), and tool-call argument injection across execution nodes.
Instruction Override
Many-Shot Bias
Authority Spoofing
Multi-layer provenance controls that persist attribution through paraphrasing, semantic rewriting, and back-translation, with keyed cryptographic verification for tamper evidence.
Data spread across cloud, on-prem, and legacy systems makes integration and consistency difficult. We unify it all into a single reliable platform.
From Data Mesh and Data Fabric to AI-ready data foundations, we address systemic risks across data quality, governance, model safety, and continuous adversarial validation to ensure production-grade, policy-compliant AI outcomes.
Coverage includes direct and indirect prompt injection, jailbreak escalation, retrieval-context poisoning, tool-call abuse, and policy-evasion chains. Audits include Quick Probe, Baseline, and Advanced multi-step testing with risk-ranked remediation mapped to refusal integrity, harmful-output suppression, and compliance logic controls.
Programs follow a control-gated lifecycle: baseline architecture assessment, target-state blueprinting, dependency-aware migration waves, and production operating model rollout. Delivery includes lakehouse reference architectures, pipeline CI/CD, SLO-driven observability, incident runbooks, and ownership handoff aligned to platform and data-product teams.
Integration uses CDC, event streaming, and batch ELT with schema registry, contract validation, and idempotent processing guarantees. Canonical data models, lineage propagation, and policy-controlled access keep cross-system joins reliable under schema evolution and upstream volatility.
Scalability is engineered through autoscaling compute tiers, partition-aware execution plans, stateful streaming checkpoints, and workload isolation by SLA class. Pipelines are tuned with adaptive query execution, optimized storage layouts, and back-pressure controls for predictable throughput from batch to low-latency streaming.
Critical criteria include workload criticality scoring, dependency graph analysis, target-state architecture fit, metadata and lineage completeness, policy enforcement boundaries, SLO baselining, and rollback-safe cutover design. Decisions are validated against cost-performance envelopes, compliance constraints, and operational blast-radius thresholds.
Enforcement uses RBAC and ABAC policies, column and row-level security, dynamic masking, tokenization, and KMS-backed encryption in transit and at rest. Delivery includes retention and deletion automation, immutable audit trails, and continuous policy-drift detection for audit readiness.
Workstreams include source-system decomposition, legacy-to-lakehouse migration, medallion model implementation, orchestration of batch and stream pipelines, data quality rule engines, lineage and governance controls, and AI-ready feature or data product enablement with deployment guardrails.
Teams gain deterministic data products, lower p95 latency, improved freshness and quality SLA attainment, and reduced reconciliation toil through automated controls. Operationally this lowers incident rate and MTTR while increasing release cadence and model/BI reliability under production load.
Supported integrations span Databricks Lakehouse, Azure/AWS/GCP analytics services, Spark/Kafka ecosystems, dbt transformation layers, vector stores, and managed ingestion connectors. Deployments are delivered with IaC, environment promotion pipelines, and policy-consistent multi-cloud or hybrid runtime patterns.
Implementation emphasizes platform-specialist engineering over template-only delivery: performance-tuned data architecture, governance-by-design, adversarially validated AI safety controls, and measurable reliability and compliance KPIs. Engagements include production hardening, failure-mode analysis, and operational readiness criteria before handoff.
Both models are supported: targeted architecture advisory and full lifecycle build-run operations. Lifecycle scope includes design, implementation, validation, release engineering, SLO governance, and managed support with escalation and on-call models aligned to enterprise accountability requirements.


